


The C and C++ Programming Languages
Page presents notes on various C and C++ features, for example C++11 rvalue references, using the C preprocessor for stringization etc etc...
Page Contents
References
- Well Known Pre-Define Compiler Macros.
- Compiler Explorer
- Introducing the Move Constructor, by Smart Bear Software.
- C++11 Biggest Changes, by Smart Bear Software.
- C++ Notes for Professionals Book, GoalKicker.com.
- Distcc - Distributed Compiling
Todo/To Read
- A Proposal to Add Move Semantics Support to the C++ Language
- Move Constructors
- Traits: The else-if-then of Types
- The Design Is In The Code
- Generic: Change the Way You Write Exception-Safe Code — Forever
- The Biggest Changes in C++11 (and Why You Should Care)
- New features in C++11 for LHCb Physicists
- C++11 - the new ISO C++ standard
- Good sockets tutorial - http://beej.us/guide/bgnet/html/single/bgnet.html
- http://www.cs.rpi.edu/~moorthy/Courses/os98/Pgms/socket.html
- http://www.alexonlinux.com/signal-handling-in-linux
- http://www.netzmafia.de/skripten/unix/linux-daemon-howto.html
- http://www.informit.com/articles/article.aspx?p=397655&seqNum=6
- https://computing.llnl.gov/tutorials/pthreads/
- http://stackoverflow.com/questions/17954432/creating-a-daemon-in-linux
- https://www.freedesktop.org/software/systemd/man/daemon.html
- http://advancedlinuxprogramming.com/alp-folder/
- https://linux.die.net/man/3/daemon
- http://stackoverflow.com/questions/22409780/flock-vs-lockf-on-linux
- https://balau82.wordpress.com/2010/10/06/trace-and-profile-function-calls-with-gcc/
- https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
- https://en.wikipedia.org/wiki/Restrict
- http://www.inf.ed.ac.uk/teaching/courses/copt/
- http://cellperformance.beyond3d.com/articles/2006/05/demystifying-the-restrict-keyword.html
- std::find and std::remove to delete from vector (http://stackoverflow.com/questions/39912/how-do-i-remove-an-item-from-a-stl-vector-with-a-certain-value)
- http://stackoverflow.com/questions/610245/where-and-why-do-i-have-to-put-the-template-and-typename-keywords
- Casts and inheritance static vs dynamic -- http://ideone.com/J7hUIw
- Access specifier on inheritance - https://ideone.com/gg19T4
- https://herbsutter.com/2008/01/01/gotw-88-a-candidate-for-the-most-important-const/
- http://stackoverflow.com/questions/2784262/does-a-const-reference-prolong-the-life-of-a-temporary
- http://ideone.com/0Ff84V
- http://stackoverflow.com/questions/4908539/a-way-in-c-to-hide-a-specific-function
- https://en.wikipedia.org/wiki/Double_dispatch
- https://en.wikipedia.org/wiki/Virtual_method_table
- http://stackoverflow.com/questions/1872220/is-it-possible-to-iterate-over-arguments-in-variadic-macros
- https://channel9.msdn.com/Series/C9-Lectures-Stephan-T-Lavavej-Core-C-
- https://github.com/isocpp/CppCoreGuidelines
- http://stackoverflow.com/questions/9599807/how-to-add-indention-to-the-stream-operator
- http://stackoverflow.com/questions/411103/function-with-same-name-but-different-signature-in-derived-class
and my test http://ideone.com/BPeDtm - https://vimeo.com/97337253
- https://vimeo.com/97337258
- https://vimeo.com/97329153
- https://vimeo.com/97318797
- https://vimeo.com/97315939
- https://vimeo.com/68390510
- https://vimeo.com/68390509
- https://vimeo.com/68390478
- https://github.com/Kitware/KWStyle
- http://www.suodenjoki.dk/us/archive/2010/cpp-checkstyle.htm
- https://stackoverflow.com/questions/5195990/using-boostaccumulators-how-can-i-reset-a-rolling-window-size-does-it-keep-e
- https://eli.thegreenplace.net/2014/variadic-templates-in-c/
- https://stackoverflow.com/questions/24371868/why-must-a-short-be-converted-to-an-int-before-arithmetic-operations-in-c-and-c
- https://stackoverflow.com/questions/490773/how-is-the-c-exception-handling-runtime-implemented
- https://www.jjj.de/fxt/ - FXT: a library of algorithms
- https://secure-media.collegeboard.org/apc/ap01.pdf.lr_7928.pdf
- https://baptiste-wicht.com/posts/2012/04/c11-concurrency-tutorial-advanced-locking-and-condition-variables.html
- http://www.hboehm.info/gc/ - garbage collected for c/c++??
- ftp://ftp.sas.com/techsup/download/SASC/share5958-59/S5958v2.pdf
- http://www.eecs.umich.edu/courses/eecs489/w07/LectureSlides/socketProgramming.pdf
- http://tldp.org/LDP/lpg/node11.html
- https://blog.smartbear.com/codereviewer/c11-a-new-c-standard-aiming-at-safer-programming/
- http://fileadmin.cs.lth.se/cs/education/EDAN25/F06.pdf
- http://www.drdobbs.com/cpp/c-finally-gets-a-new-standard/232800444
- http://www.drdobbs.com/cpp/the-new-c-standard-explored/232901670?pgno=2
- http://www.open-std.org/JTC1/SC22/WG14/www/docs/n1516.pdf
- https://stackoverflow.com/questions/1393443/setjmp-longjmp-and-local-variables
- https://hackerboss.com/overriding-system-functions-for-fun-and-profit/
- https://github.com/angrave/SystemProgramming/wiki/Signals,-Part-2:-Pending-Signals-and-Signal-Masks
- https://www.gnu.org/software/global/
- https://github.com/jsfaint/gen_tags.vim
- https://github.com/universal-ctags/ctags
- https://stackoverflow.com/questions/98650/what-is-the-strict-aliasing-rule
- https://opensourceforu.com/2015/03/be-cautious-while-using-bit-fields-for-programming/
Online Work Pads (Compilers and Code Analysers)
The following are quite good online "work pads" for testing out snippets of code and investigating the behaviour of a bit of code across several compilers (or at least versions of).
- http://ideone.com
- http://coliru.stacked-crooked.com
- http://webcompiler.cloudapp.net - for microsoft VC only
- http://rextester.com/runcode
- http://www.onlinegdb.com
- https://wandbox.org
- cpp.sh
- CPP Code Benchmarking.
To compare compilers and view the output assembler try there:
Compilation Flags (GCC)
Useful flags, mostly warning-enablers, to add to builds...
| Option | Meaning |
-Wall | Enables lots of warnings, but not everything. |
-Wextra | Enables some extra warning flags that are not enabled by -Wall. |
-Wshadow | Warn whenever a local variable or type declaration shadows another variable, parameter, type, class member etc. |
-Werror | Converts all warnings to errors. |
-Wfloat-equal | Warn if floating-point values are used in equality comparisons. . |
-Wcast-align | |
-Wpointer-arith | |
-Wmisleading-indentation | Warn when the indentation of the code does not reflect the block structure. |
-Wuninitialized | |
-pedantic | Requires Strict ISO C[++] and reject forbidden language extensions. |
-pedantic-errors | Turns -pedantic warnings into errors. |
-Wconversion | Warn for implicit conversions that may alter a value. |
-Wsign-conversion | Warn for implicit conversions that may change the sign of an integer value. |
-g | For debug information. |
-rdynamic | |
-Wno-long-long | Do NOT warn if long long type is used. |
-O[s0-?] | Optimize for space or speed. |
-E | Produces only the preprocessor output. |
-S | Produces only the assembly code. Combine this with -fverbose-asm to add informative comments to the assembly output. |
-fPIC | For shared libraries produce position independent code. |
-D | Define macro on the command line. |
-fcheck-pointer-bounds | Enable Pointer Bounds Checker instrumentation. Each memory reference is instrumented with checks of the pointer used for memory access against bounds associated with that pointer. |
-Wdouble-promotion | Give a warning when a value of type float is implicitly promoted to double. |
Debugging
Instrumenting Functions
Use GCC compiler option "-finstrument-functions" and implement these functions:
void __cyg_profile_func_enter (void *, void *) __attribute__((no_instrument_function)); void __cyg_profile_func_exit (void *, void *) __attribute__((no_instrument_function));
For Windows see this SO thread. It shows how to use
the /Gh and /GH penter/pexit hooks.
Valgrind
valgrind \
--tool=memcheck \
--track-origins=yes \
--num-callers=30 \
--leak-check=full \
--show-reachable=yes \
--leak-resolution=high \
--trace-children=yes \
-v \
path/to/binary <args for binary>
Tagging Your Source Code: GNU Global
References
- GNU GLOBAL Source Code Tagging System, Offical GNU Global Page.
Install
Check for the most recent version and use commands like this:
mkdir deleteme pushd deleteme/ wget http://tamacom.com/global/global-6.6.2.tar.gz tar xvf global-6.6.2.tar.gz cd global-6.6.2/ ./configure make all sudo make install popd rm -fr deleteme
Cheat Sheet
All the global commands must be run from within your project directory structure. I.e., from the root directory or a subdirectory.
| Build Index: | gtagsMust be run from project ROOT! Requires considerable disk space! |
| Find something: | global "posix regular expr" |
| Find references: | global -r ... |
| Include details: | global -x ... |
| Find lines matching pattern: | global -g "posix regular expr" |
| Only search CWD: | global -l ... |
| Invert match: | global -V ... |
| Case insensitive matches: | global -i ... (not default!) |
| Definitions: | global -d ... |
| Auto complete: | global -c ... |
| Update tag files incrementally: | global -u (can be done from any dir) |
| Update gtags for specific file: | gtags --file file |
Static Analysers
scan-build
https://askubuntu.com/questions/1033808/how-can-clang-static-analyzer-scan-build-be-installed-on-ubuntu-18-04
CPPCheck
https://stackoverflow.com/questions/27552188/how-do-i-install-cppcheck-using-the-tar-file-on-linux
FlawFinder
https://dwheeler.com/essays/static-analysis-tools.html
C++ Core Guidelines
Written by Bjarne Stroustrup and Herb Sutter.
Preprocessor Stringization
Stringize Parameter Tokens
To convert the expression passed as a macro parameter to a string use the # operator:
If ... a parameter is immediately preceded by a # ... both are replaced by a single character string literal preprocessing token that contains the spelling of the preprocessing token sequence for the corresponding argument.
In fact, the standard goes on to mention other conditions such that "#x"
is replaced with the result of the pseudo code "strip(escape(collapse_consequtive_whitespace(string(arg)))".
The macro argument in the replacement list is first converted to a string. Any consecutive
whitspace sequences are converted to just one whitespace, then " is espaced to \",
then any preceeding or trailing whitespace is stripped.
It is the above beviour that allows the following (contrived example) to work:
#include <stdio.h>
#define str(x) #x
int main(void) {
printf(str(jehtech says "hi" \t to you all));
return 0;
}
/*
* Printf preprocesses to (use -E gcc option):
* printf("jehtech says \"hi\" \t to you all");
* ^^^ ^^
* ^^^ Notice how " has been replaced with \"
* Notice how whitespace has been collaped
* OUTPUTS:
* jehtech says "hi" <tab-char> to you all
*/
Notice how the whitespace between "jehtech" and "says" has been collapsed into one space and how the " has been escaped to \" (must have been otherwise we'd get a compile error).
#x in a macro replacement list is replaced by the result of the pseudo code "strip(escape(collapse_consequtive_whitespace(string(arg))) "
For (another) example, the following defines (a rather junk, but served to illustrate) assert macro:
#include <stdio.h>
#define ASSERT_EQ(exp, val) \
do { \
if ((exp) != (val)) \
fprintf(stderr, "ASSERTION FAILURE: " #exp " != " #val); \
exit(1); \
} while(0)
int main(void)
{
ASSERT_EQ(4 + 5, 1);
return 0;
}
/*
* Outputs to STDERR:
* ASSERTION FAILURE: 4 + 5 != 1
*/
In the macro line fprintf(stderr, "ASSERTION FAILURE: " #exp " != " #val),
the parameters exp and val are preceded by a #. The preprocessor
evaluated the macro use and replaces #exp with the string containing preprocessing token sequence:
"4 + 5". Same for #val. Hence the output of the program.
Glue Parameter Tokens
Another very useful feature is the ability to glue tokens together using ##:
If ... a parameter is immediately preceded or followed by a ## preprocessing token, the parameter is replaced by the corresponding argument’s preprocessing token sequence ...
One example of how you might "glue" a parameter's token sequence together with other tokens is shown below.
#include <stdio.h>
#include <stddef.h>
#define DEF_STRUCT_FOR_OFFSET(type) \
struct type##OffsetStruct { \
char dummy; \
type value; \
}
DEF_STRUCT_FOR_OFFSET(int);
DEF_STRUCT_FOR_OFFSET(long);
DEF_STRUCT_FOR_OFFSET(double);
int main(void)
{
printf("Alignment required for int is %d bytes\n", offsetof(struct intOffsetStruct, value));
printf("Alignment required for long is %d bytes\n", offsetof(struct longOffsetStruct, value));
printf("Alignment required for double is %d bytes\n", offsetof(struct doubleOffsetStruct, value));
return 0;
}
/*
* The line "DEF_STRUCT_FOR_OFFSET(int);" expands to:
* struct intOffsetStruct { char dummy; int value; };
* ^^^
* Notice the ## glue at work
* Same applies to the other similar lines.
*/
The line of interest is "struct type##OffsetStruct. When the preprocessor
sees a use of the macro it replaces the parameter "type##" with
its tokens. Note, unlike a single # the tokens are not not converted into a string.
They are just pasted as tokens in the program. Hence, "DEF_STRUCT_FOR_OFFSET(int)"
declares a structure named "intOffsetStruct". Hence the
description of ## as "glue".
Note the ## tokens can surround a parameter name, so you can "glue" on both sides.
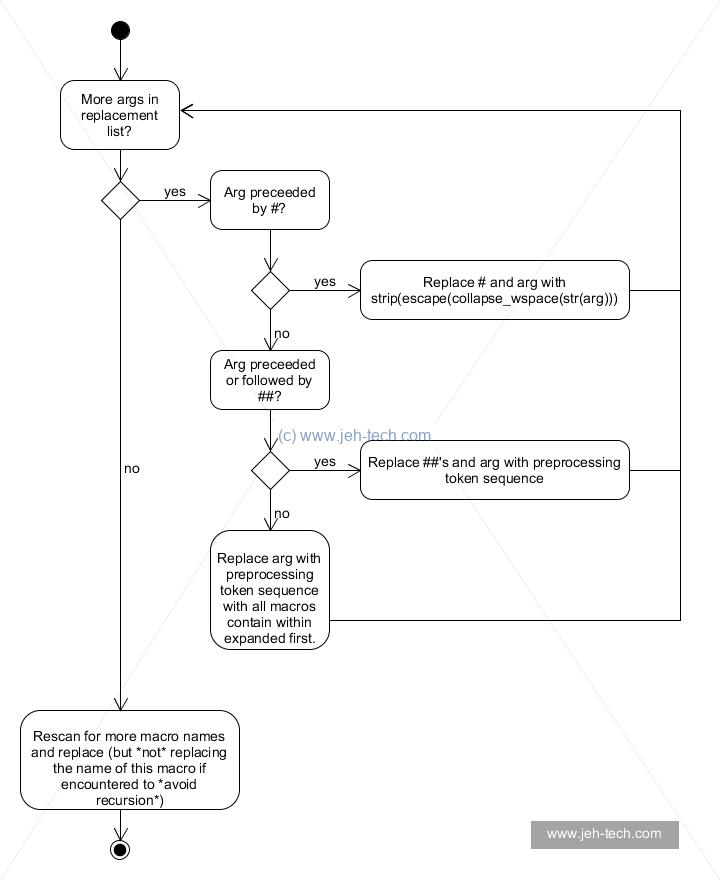
Summary Of Macro Expansion
Stringize The Result Of Expansion
If we change the example you saw for the stringize example slightly as shown below, we'll get a slightly unexpected outcome:
#include <stdio.h>
#define ASSERT_EQ(exp, val) \
do { \
if ((exp) != (val)) \
fprintf(stderr, "ASSERTION FAILURE: " #exp " != " #val); \
exit(1); \
} while(0)
#define JUNK_SUM (4 + 5)
int main(void)
{
ASSERT_EQ(JUNK_SUM, 1);
return 0;
}
/*
* Outputs to STDERR:
* ASSERTION FAILURE: JUNK_SUM != 1
*/
The output is "JUNK_SUM != 1". Why was it this, and not "(4 + 5) != 1"?!
Let's be the preprocessor and follow the flow chart above. We find the macro invocation
ASSERT_EQ(JUNK_SUM, 1) and determine that the arguments are exp == JUNK_SUM
and val == 1. We now look through the macro's replacement token sequence.
The first place in which arguments are encountered is in the line if ((exp) != (val)).
Here neither argument is preceeded by a # or ##, and in the case of a ## neither is followed by a ## either.
So, we replace the arguments in the preprocessing token sequence with the arguments fully expanded.
Therefore val is replaced with 1. As 1 is just a literal it cannot be
expanded further. We reaplce exp with JUNK. This is another macro, so
we fully expand that first to get (4+5). This is now fully expanded (but if there
had been any macros encountered in the expansion we would have recursively continued to expand everything).
Thus exp gets replaced with (4+5) to yield if (((4+5)) != (1)).
That went well. So we keep evaluating the macro's replacement token sequence. we encounter both
#exp and #val again, except this time they are both preceeded by
a # symbol. So now we would replace #exp with the result of
strip(escape(collapse_consequtive_whitespace(string(JUNK))). Ah, we just
converted the token JUNK to the string "JUNK". Ooops. Same for #val,
that got expanded to the string "1".
Now that all the arguments in the macros replacement list have been expanded we would rescan for more macro names and replace, but now JUNK does not exist as a preprocessing token but as a plain string, so we do nothing more to it. Hence we print out "ASSERTION FAILURE: JUNK_SUM != 1".
So... in summary, the reason is that the preprocessor evaluates/strigizes #exp before expanding
out exp. Thus it gets the string "JUNK_SUM".
BUT.... We'd like it to print out "(4 + 5) != 1". How can we accomplish this? The code snippet below shows us how...
#include <stdio.h>
#define xstr(x) str(x)
#define str(x) #x
#define ASSERT_EQ(exp, val) \
do { \
if ((exp) != (val)) \
fprintf(stderr, "ASSERTION FAILURE: " xstr(exp) " != " #val); \
exit(1); \
} while(0)
#define JUNK_SUM (4 + 5)
int main(void)
{
ASSERT_EQ(JUNK_SUM, 1);
return 0;
}
Why does it work? In xstr(exp), the argument exp is first
replaced to give xstr((4+5)). But the expansion continues until everything is
fully expanded out, so now xstr((4+5)) is expanded out to #(4+5).
Not this is expanded out to the string "(4+5)". Hence we can print out
what was in JUNK_SUM instead of the string "JUNK_SUM". We can
apply to same technique for as many levels of macro as the real thing we want to stringize is
behind :)
Some Play
Some little playing in C: reading a file line by line and an enhanced strok function.
LValues, RValues etc
LValues
First some terminology. In C, an object is just a region of data storage that represents a value. Why does the standard talk about "data storage"? I think this is because we could mean RAM, a register, ROM or any other kind of memory. It's just a generic term; an abstraction.
In the standard, an expression is a sequence of operators and operands that,
- computes a value, or
- results in an object (a region of data that can represent a value), or
- results in a function, or
- generates side effects, or
- is some combination of any of the above
In C & C++ an lvalue is defined as:
An lvalue is an expression with an object type or an incomplete type other than void ... When an object is said to have a particular type, the type is specified by the lvalue used to designate the object ...
... Except when it is the operand of the sizeof operator, the unary & operator, the ++ operator, the -- operator, or the left operand of the . operator or an assignment operator, an lvalue that does not have array type is converted to the value stored in the designated object (and is no longer an lvalue) ...
What does an expression with an object type
mean? It is just an expression
that results in an object, i.e., an area of memory we can name (identify) in our
program.
An lvalue has to designate an object
. This means that an lvalue has to
be something that we can use, in our program, to locate an object. I.e. it has to
be a name that we can use to access an area of memory that represents a value of some type:
it is an object locator
. It could also be thought of as an address that is
stored into
[Ref].
Because an lvalue represents some value in data storage it can persist beyond its current expression. The lvalue represents a way to locate an object (region of data storage).
If we assign into something, we must be assigning into an lvalue because we need to store the value in an object, i.e., an area of data storage that can hold the value and that we can locate via a name in our program. Thus A = B requires that A be an lvalue. It must also be modifiable, so not const!
So, straight away, we can tell that literals are not lvalues. For example the literal 123.321 does is not represented by a region of data storage. It's just a number that exists at compile time. double x = 123.321 is however an expression that creates a region of data storage, refered to by the variable named x. This region of data storage represents the literal 123.321 and is therefore an lvalue.
Also, lets say that a function returns a pointer to an integer, then *(some_function()); must also be an lvalue because it yields the region of data storage that represents a value, even if we don't do anything with it.
An interesting example is this:
int a = 1; int b = 3; a + b = 22;
Obviously we can't do this because we intuitively know that one cannot assign a value into an expression because the value a + b is just that, a temporary value. However, this temporary value must exist in memory, even it it is only temporarily in a register.
The variables a and b are lvalues, but they may only exist in a
register. But so would the result a + b, so just having some storage isn't quite enough, it would seem.
The answer comes from the second paragraph in the definition: an lvalue [when used as an operand] ... is converted to the
value stored in the designated object (and is no longer an lvalue)
. Ah ha! In the
expression a + b, the operands are converted to values and are no longer lvalues,
hence the result is not an lvalue. This gives a standards-based explanation of our intuition :)
The important thing to note is that the is no name (designator) that we can use to access
the temporary value resulting from a + b, in this case.
And to just be double sure that we're on the right track, Thomas Becker's article C++ Rvalue References Explained has this to say:
An lvalue is an expression that refers to a memory location and allows us to take the address of that memory location via the & operator.
C only really talks about lvalues. Rvalues are mentioned in the standard, but only once: What is sometimes called rvalue is in this International Standard described
as the value of an expression
. Thus rvalues are just really anything that isn't an lvalue.
Scott Meyers also says a similar thing:
An lvalue is something you can typically make an assignment too, or take its address ... it has a name ...
In Scott Meyer's talk (admittedly about C++ but the same applies for C in the case of lvalues) he gives these examples:
int x = 22; const int cx = x;
The variable x is an lvalue because it has a name, you can take its address and you can assigned to it.
The variable cx is also an lvalue. You can't assigned to it, but it has a name and you can therefore take its address.
C++11: RValues, RValue References & Universal References
First some references:
- Universal References in C++11, Scott Meyers
- C++ Rvalue References Explained, Thomas Becker
C++ has quite a few more types!
An xvalue (an eXpiring value) also refers to an object, usually near the end of its lifetime (so that its resources may be moved, for example). An xvalue is the result of certain kinds of expressions involving rvalue references (8.3.2).
A glvalue (generalized lvalue) is an lvalue or an xvalue.
An rvalue ... is an xvalue, a temporary object (12.2) or subobject thereof, or a value that is not associated with an object.
A prvalue (pure rvalue) is an rvalue that is not an xvalue. [ Example: The result of calling a function whose return type is not a reference is a prvalue. The value of a literal such as 12, 7.3e5, or true is also a prvalue ... ]
Oh man! Read the standards docs really isn't easy... eek!
We can gleam that an rvalue is something that is about to expire (its lifetime is over), a temporary object (like the result of A * B, for example) or a value that is not addressable.
This implies it is something that is short lived and won't be used or have side effects almost
immediately after its last reference. For example, in the expression a = b * c,
the result of b * c is a temporary object and we can't take it's address.
This gives us some idea: rvalues are things we can't really access in our code in
any meaningful way. They are transients that exist to accomplish a task. So if
b * c involves two matrix classes and they both are large matricies, why
copy the result into a? Why not just let a have the resources of the temporary result
instead of copying the temporary into a and then destroying the temporary? Could save
ourselves a huge copy operation. This is one of the key motivations for rvalue references.
Now though, I'm going to use the referenced articles as the standard isn't something that I would call a "learning/teaching resource". The rest of this is just notes on the referenced, as I'm still getting to grips with the RValue and Universal references!
Expanding on the previous quote by Scott Meyers:
An rvalue, generally speaking, is a temporary object ... Rvalues have no name and you can’t take their address ...
Continuing with Thomas Becker's article...
Move semantics means swapping resource handles between an lvalue and a temporary (rvalue).
If matricies are classes with large data the code matrixA = matrixB * matrixC
constructs a temporary object to represent the result of the multiplication and then copies
that data into matrixA. A copy has been wasted! The temporary's resources could
just be transfered rather than copied!
This needs some kind of "move constructor", a lot like a "copy constructor", but which moves the resources instead of copying them. The type that allows us to do this is the rvalue reference, represented by a double ampersand (&&) (or as Scott Meyers calls them, Universal References because they may actual refer to either an lvalue of an rvalue in some cases):
Matrix& Matrix::operator=(Matrix&& rhs)
// ^^
// New type: rvalue reference
{
// ...
// swap this->mArrayOfValues and rhs.mArrayOfValues
// ...
}
- RValue references are prefered by rvalues. LValues prefer lvalue references.
- RValues allow a function to branch at compile time (via overload resolution) on the condition "Am I being called on an lvalue or an rvalue?"
RValue references are prefered by rvalues. LValues prefer lvalue references. RValues allow a function to branch at compile time (via overload resolution) on the condition "Am I being called on an lvalue or an rvalue?"
MSVC
C/C++ Run Time Library (RTL)
In MSVC projects you can either statically or dynamically link against the run time library.
The C and C++ RTL libraries include the standard C/C++ functions that the standards
require. So, in C, it is functions like malloc(), memcpy() etc etc,
and in C++ it is these and the C++ STL.
When using MSVC, different versions have different RTLs and for each version there are several variants depending on whether you are compiling for debug or release and whether you static vs dynamic linking. Note: there are only multi-threaded libraries available (there used to be single threaded but no more).
To statically link against the RTL implies that the RTL code is linked into your program so that your program does not have any external dependencies as far as using the C/C++ standard library functions goes.
To dynamically link against the RTL means that your program is compiled without the RTL "backed in" and thus requires a certain set of DLLs, which must be present on the host when your program is executed.
The former has the advantage that you don't care whether your host has the correct RTL installed (because your program already contains all the RTL functions it needs) but the disadvantage that it is slightly bigger. The latter has the advantage that it will be slightly smaller (and if there was a patch etc to the RTL you wouldn't have to redistribute your app), but it has the disandvantage that the host must have the correct RTL DLLs available and if it doesn't you have to distribute them.
In debug libraries, the debug symbols are generated (.pdb) files and no opimization is used. In release libraries, symbols are stripped and code optimization is used.
Your link options are [Ref]:
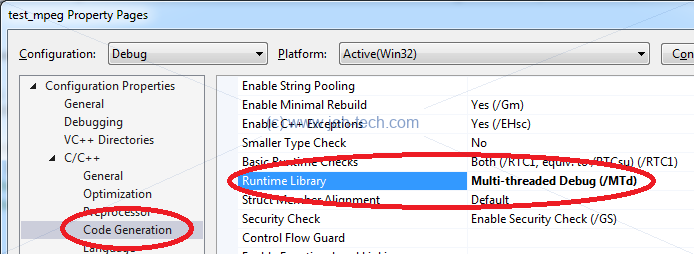
/MD[d]:Use multi-threaded dynamic RTL. No 'd' for release, 'd' for debug./MT[d]:Use multi-threaded static RTL. No 'd' for release, 'd' for debug.
Casting in C & C++
C v.s. C++
In C there is no checking done when you make a cast. You can cast from any type to another and the compiler will not complain. In C++, C-style casts should be avoided because the C++ casts offer a safer way to cast.
Casts Are More Than Treating One Type As Another!
Interestingly a cast may do more than just "switching" types. The compiler may have to generate extra code to achieve this!
Many programmers believe that casts do nothing but tell compilers to treat one type as another, but this is mistaken. Type conversions of any kind (either explicit via casts or implicit by compilers) often lead to code that is executed at runtime.
The referenced chapter is particularly illuminating. It explains why dynamic_casts
can be "expensive" - many compilers will do string compares on class names
to perform the RTTI. I guess they might store a type variable behind the scenes
that the compiler generate code to check against. (Need to reed up on this lol)
For example, let's use godbolt.org to examine what happens when we cast from an integer to a double:

Although we have turned off optimizations (we have to otherwise the entire bit of code in the example gets optimized away)
we can see what the compiler has had to do to cast the int to a double: it has had to
emit the instructions vmov and vcvt.f64.s32 to accomplish the cast. The latter
command is what converts between an integer and a double and the former puts the integer in an appropriate register.
Thus our cast has resulted in extra machine instructions.
Static & Reinterpret Casts
A static cast converts betwen related types, but will not allow you to convert between unrelated types. For example, a static cast will not cast away constness or volatility.
When you static_cast you're basically saying to the compiler that
you guarantee that the type is what you say it is. This means, especially for
down-casts from base classes to child classes, the compiler won't emmit code to
do run time checks. Thus static_cast is less safe. It may still
emmit code to do the cast, just not the type checking code.
Reinterpret casts are even more unsafe and let you convert between unrelated types...
Unlike static_cast, but like const_cast, the reinterpret_cast expression does not compile to any CPU instructions. It is purely a compiler directive which instructs the compiler to treat the sequence of bits (object representation) of expression as if it had the [new type].
Stroustrup explains this in more detail
here.
He says that the idea is that conversions allowed by static_cast are somewhat
less likely to lead to errors than those that require reinterpret_cast
, and
gives the following example:
int a = 7; double* p1 = (double*) &a; // ok (but a is not a double) double* p2 = static_cast<double*>(&a); // error double* p2 = reinterpret_cast<double*>(&a); // ok: I really mean it
Todo:
https://stackoverflow.com/questions/14623266/why-cant-i-reinterpret-cast-uint-to-int
IOStreams
Output Stream Manipulators
Manipulators are objects known to IOStream that allows a stream to be changed. Include
<iomanip>. Mostly, states are persistent.
cout.put(c) | Write char c to stdout. |
std::endl | Writes a newline ("\n") then calls cout.flush(). Note this is not a cross platform newline which is sometimes a confusion. It just outputs "\n", not "\r\n" or anything else. |
std::flush | Calls cout.flush(). |
std::ends | Prints NULL character to cout. |
setw(c) | Sets c as the stream's fill character. |
setfill() | Sets field width. Default is right aligned. |
cout.setf(flag-to-set, flag-to-clear) | flag-to-clear, the second parameter clears all flags before setting flag-to-set. |
cout.unsetf(flag-to-clear) | Clear a flag. |
ios::hex ios::oct ios::dec | For integer output. |
ios::basefield | Mask to clear all integer output formats. |
ios::showbase | Puts a "0x" in front of hex output etc. |
ios::showpos | Shows the positive sign for values. |
cout.precision() | Sets precision of floating point output. | ios::fixed ios::scientific |
ios:uppercase | Force hexadecimal alpha characters to uppercase. |
ios:left | Sets left alignment when field width greater than width of whats being printed. |
ios::adjustfield | Mask to clear all alignments. |
(void *) | Cast any pointer to void * to print the pointer |
Input Streams
By default input streams ignore whitespace.
Usually line buffered. I.e. cin >> var; will not return until RETURN is pressed.
Quietly go into a safe, do-nothing, mode upon error.
Read/Write Containers to Files
template <typename T>
void VectorFromFile(const std::string &filename, std::vector<T> &v)
{
std::copy(
std::istream_iterator<T>(std::ifstream(filename.c_str())),
std::istream_iterator<T>(),
std::back_inserter(v));
}
template <typename T>
void VectorToFile(const std::string &filename, const std::vector<T> &v)
{
std::copy(
v.begin(),
v.end(),
std::ostream_iterator<T>(std::ofstream(filename.c_str()), "\n"));
}
Google Test (On Windows)
Jeez it took ages to set this bugger up... so save yourself some time and don'try to open the existing msvc project files and instead re-generate them using cmake! I promise you it will save you the heart-ache. These are the steps:
- Download and install CMake and make sure you select the option to put CMake on the path
- Pick a root directory and clone the CMake git repo there. I'm gonna use
C:\Users\jehtech\googletest_msvc. Therefore from the git command prompt naviage to/c/users/jehtech/googletest_msvcand typegit clone git@github.com:google/googletest.git. This will create the subdirectorygoogletest. - Absolutely ignore the existing MSVC project files in
C:\Users\jehtech\googletest_msvc\googletest\googletest\msvc!! - From the same directory, but in your normal console, type
cmake -Dgtest_build_samples=ON googletest_msvc. Using-Dgtest_build_samples=ONtells CMake to generate project files that contain the Google Test examples as well. - CMake should now generate your MSVC project files for you in the directory
C:\Users\jehtech\googletest_msvc. - Load the project file
googletest-distribution.slnand build the solution for both Debug and Release. This will create the directoriesC:\Users\James\googletest_msvc\googlemock\gtest\{Debug,Release}that contain the built gtest libraries.
But annoyingly I still get the following when trying to create my own project, although the sample tests do not seem to have this problem for some reason.
Severity Code Description Project File Line Suppression State Error C2440 '': cannot convert from 'initializer list' to 'testing::internal::AssertHelper' test_mpeg c:\users\james\documents\git\mpeg_ts_messing\gtest\src\gtest_binary_buffer.cpp 12 Severity Code Description Project File Line Suppression State Error C2065 'gtest_ar': undeclared identifier test_mpeg c:\users\james\documents\git\mpeg_ts_messing\gtest\src\gtest_binary_buffer.cpp 12 Severity Code Description Project File Line Suppression State Error C2589 'switch': illegal token on right side of '::' test_mpeg c:\users\james\documents\git\mpeg_ts_messing\gtest\src\gtest_binary_buffer.cpp 12 Severity Code Description Project File Line Suppression State Error C2181 illegal else without matching if test_mpeg c:\users\james\documents\git\mpeg_ts_messing\gtest\src\gtest_binary_buffer.cpp 12
Smart Pointers
Defined in <memory>
Shared Pointers
For shared ownership use shared_ptr. You can have many shared pointers pointing at the
same object. That object is only freed when the number of pointers to the object
reaches 0.
For shared use where ownership is not required weak_ptr is used.
#include <memory>
#include <iostream>
#include <vector>
class Transformer
{
protected:
std::string mName;
public:
Transformer(const std::string &name) : mName(name) { }
std::string GetName() { return mName; }
};
class Autobot : public Transformer
{
public:
Autobot(const std::string &name) : Transformer(name) { }
~Autobot() { std::cout << "** Deleting Autobot " << mName << std::endl; }
};
class Decepticon : public Transformer
{
public:
Decepticon(const std::string &name) : Transformer(name) { }
~Decepticon() { std::cout << "** Deleting Decepticon " << mName << std::endl; }
};
int main(int argc, char *argv[])
{
// Note in C++11 No longer need space between two template endings: >> not >space>
std::vector<std::shared_ptr<Transformer>> characters;
std::shared_ptr<Transformer> pOptimusPrime(new Autobot("OptimusPrime"));
std::shared_ptr<Transformer> pBumblebee(new Autobot("Bumblebee"));
{
std::shared_ptr<Transformer> pMegatron(new Decepticon("Megatron"));
std::cout << "Before vector insertion:\n"
" Optimus has " << pOptimusPrime.use_count() << " owners\n"
" Bumblebee has " << pBumblebee.use_count() << " owners\n"
" Megatron has " << pMegatron.use_count() << " owners\n";
characters.push_back(pOptimusPrime);
characters.push_back(pOptimusPrime);
characters.push_back(pBumblebee);
characters.push_back(pMegatron);
characters.push_back(pOptimusPrime);
characters.push_back(pMegatron);
std::cout << "After vector insertion:\n"
" Optimus has " << pOptimusPrime.use_count() << " owners\n"
" Bumblebee has " << pBumblebee.use_count() << " owners\n"
" Megatron has " << pMegatron.use_count() << " owners\n";
std::cout << "\n"
"Now we'll remove the evil Megatron from the list\n";
for(auto it = characters.begin(); it != characters.end(); )
{
if((*it)->GetName() == "Megatron")
it = characters.erase(it);
else
++it;
}
std::cout << "\n"
"Removing Megatron from the list means that..\n";
std::cout << "Megatron has " << pMegatron.use_count() << " owners\n"
"Now only pMegatron holds a reference. As we go out\n"
"of scope Megatron will die!\n";
}
std::cout << "\n"
"Thankfully our other heros survived.";
std::cout << "\n"
"Because our heros are in the list, we can empty the original\n"
"smart pointers and they will continue to exist...\n";
pOptimusPrime.reset();
pBumblebee.reset();
std::cout << "\n"
"Now we exit, Optimus and Megatron should also be\n"
"destroyed (noooo, Optimus!)\n";
return 0;
}
/*
OUTPUT IS:
Before vector insertion:
Optimus has 1 owners
Bumblebee has 1 owners
Megatron has 1 owners
After vector insertion:
Optimus has 4 owners
Bumblebee has 2 owners
Megatron has 3 owners
Now we'll remove the evil Megatron from the list
Removing Megatron from the list means that..
Megatron has 1 owners
Now only pMegatron holds a reference. As we go out
of scope Megatron will die!
** Deleting Decepticon Megatron
Thankfully our other heros survived.
Because our heros are in the list, we can empty the original
smart pointers and they will continue to exist...
Now we exit, Optimus and Megatron should also be
destroyed (noooo, Optimus!)
** Deleting Autobot Bumblebee
** Deleting Autobot OptimusPrime
*/
Templates
Calling Functions In a Templated Base Class - Gotcha!
This one really surprised me! When you inherit from a base class that is a template beware calling base class functions from the derivied class. The functions names are not looked up as you'd expect (or at least how I'd have expected lol).
If in doubt, always prefix base-class function calls with "this->"!
#include <iostream>
using namespace std;
void bar()
{
std::cout << "Gloal bar()\n";
}
template <typename T>
class Base
{
public:
void bar()
{
std::cout << "Template bar()\n";
}
};
template <typename T>
class Derived : Base<T>
{
public:
void foo()
{
bar(); // WARNING! Does NOT do what you might expect!
this->bar();
Base<T>::bar();
}
};
int main()
{
Derived<int> d;
d.foo();
return 0;
}
/* OUTPUTS:
Gloal bar()
Template bar()
Template bar()
*/